EarlyPrint Library
Welcome to the EarlyPrint Library, a resource for reading and collaboratively curating a digital library of some 60,000 English books published before 1800.
The Library is based on transcriptions produced by the Text Creation Partnership (TCP). Those transcriptions could be better. You can help your fellow scholar-readers by filling in gaps and correcting small errors in the corpus. Please become an EarlyPrint Curator.
Get started by consulting the how to browse, search, and display document, or just click on Texts to begin exploring.
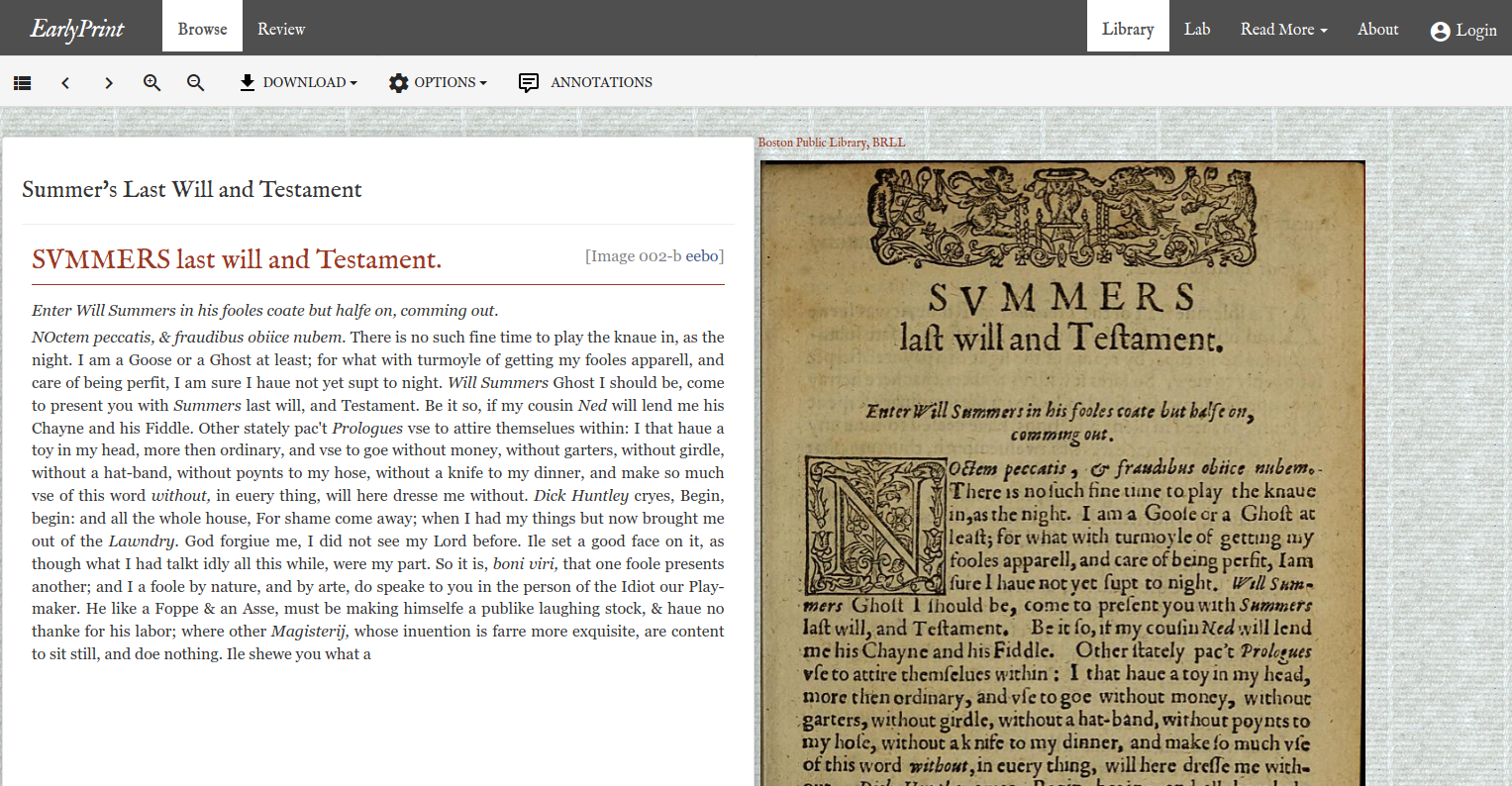
For more detail on making corrections, consult the documentation pages on textual defects and curation and quality assurance. For the unique linguistic annotation features of EarlyPrint, see the section on data enrichment. Over 700 of the texts have matching image sets, primarily from the Thomas Pennant Barton Collection in the Boston Public Library and provided here via an IIIF server at the Internet Archive. For more detail consult the section on digital combos.
The EarlyPrint Library aims to create a deduplicated digital library of most English books published before 1700 plus a sampling of mostly eighteenth-century texts from the Evans and ECCO collections. Each item in the Library will eventually be a complex digital surrogate including:
-
A reader provides a transcription that strikes a balance between being faithful to the printed source while being easy to read and use on the laptops and other mobile devices that are the “tables of memory” on which 21st-century scholars do much of their reading and writing.
-
A viewer supplements the reader with good quality page images that provide the witnesses to check the transcriptions and offer modern readers a sense of the materiality of the text in its original embodiment. For more detail on the viewer consult the section on digital combos.
-
Data files provide access to bibliographical, structural, and linguistic metadata that can be used separately or in conjunction to explore particular texts and support forms of “distant” or “scalable” reading across the entire corpus or parts of it.
-
An annotation tool supports collaborative curation and allows users to offer corrections of the most common forms of textual corruption in the transcriptions. This critical feature of the library is implemented on this site and many student- and scholar-curators have already made thousands of corrections.
You must register before you can add annotations. That is the best way of keeping track of and giving credit to curators. Tell us what is not working. There is nothing like users to discover faulty design or poor implementation, so please let us know how we can make the site better.
The ultimate goal of our project is to “re-mediate” the Early Modern print heritage, using the term as Richard Grusin and Jay Bolter did in their excellent book Remediation: Understanding New Media (MIT, 1999). We want to enhance the query potential of the complex digital surrogates that are created by an ensemble of text, image, metadata, and collaborative tools. Surrogates fall short of their originals in some ways but may exceed them in others. This is especially true of digital surrogates. To learn more about our remediation, see Martin Mueller’s account of “What is New About the EarlyPrint Library.”
Currently the site includes approximately 59,000 texts from EEBO-TCP Phases I and II, and it is our intention to add a few thousand additional EEBO-TCP texts. There are also currently about 4,000 Evans-TCP texts and 2,000 ECCO-TCP texts. As the number of texts on this site has grown, it has become increasingly necessary to filter by areas of interest rather than dealing with a list of tens of thousands of texts. There are a number of filter criteria available, and one of them is "corpus." Currently there are two corpora defined: Drama, with some 860 plays written between 1550 and 1700, and English Civil War, with a multi-genre collection of some 5,900 texts, mostly written between 1640 and 1660. Let us know what other subsets of early printed books you would like to see defined as corpora.
The Drama Corpus. Most of the texts in the drama corpus, and in particular the texts before 1642, have gone through several rounds of curation by three generations of undergraduates. Some 260 of them have matching images. About half of the plays before 1642 are proper digital combos. The majority of the images come from the Thomas Pennant Barton Collection in the Boston Public Library and are mediated over an IIIF server at the Internet Archive. For more detail consult the section on digital combos.
The English Civil War Corpus. The 5,900 texts in this corpus are a hodge-podge, consisting mostly of shorter texts ( < 50,000 words) from the English Civil War (1640-60). Only a few dozen texts are digital combos. They are mainly Civil War pamphlets, but they include Purchas His Pilgrimage, an endless but fascinating ethnographic compilation from the early seventeenth century with an image set from the Newberry Library. This text has undergone substantial curation by a group of undergraduates.
The Editors (contact us at editors@earlyprint.org):
Craig A. Berry
Philip R. Burns
Doug Knox
John Ladd
Martin Mueller
Kate Needham
Steve Pentecost